Building Observable Services: Developer Instrumentation Practices With Haylix ASSESS
Developers Build Services. Operations Observe Them.
There is a common disconnect in cloud engineering: developers design and build services, but the observability of those services in production is rarely validated until something goes wrong. By the time an on-call engineer is paging through logs during a 2am incident, it becomes clear that the service never had structured logging, that metrics were never configured, and that there is no trace data to follow.
Haylix ASSESS gives developers a structured way to validate observability coverage for the services they own before those services cause incidents they cannot diagnose.
What the Observability Pillar Checks for Developer-Owned Services
The Observability assessment evaluates each service against the instrumentation baseline that production-ready services should meet:
- Structured logging — are application logs emitting structured JSON to a centralised log store, with appropriate severity levels and contextual fields?
- RED metrics — are rate, error rate, and duration metrics instrumented per service endpoint and published to a metrics platform?
- Distributed tracing — is the service emitting trace context headers and exporting spans to a distributed tracing backend?
- Health and readiness endpoints — are liveness, readiness, and dependency health endpoints implemented and monitored?
- Alert coverage — are alerting rules defined for the service’s critical error and latency thresholds, with assigned owners and runbook references?
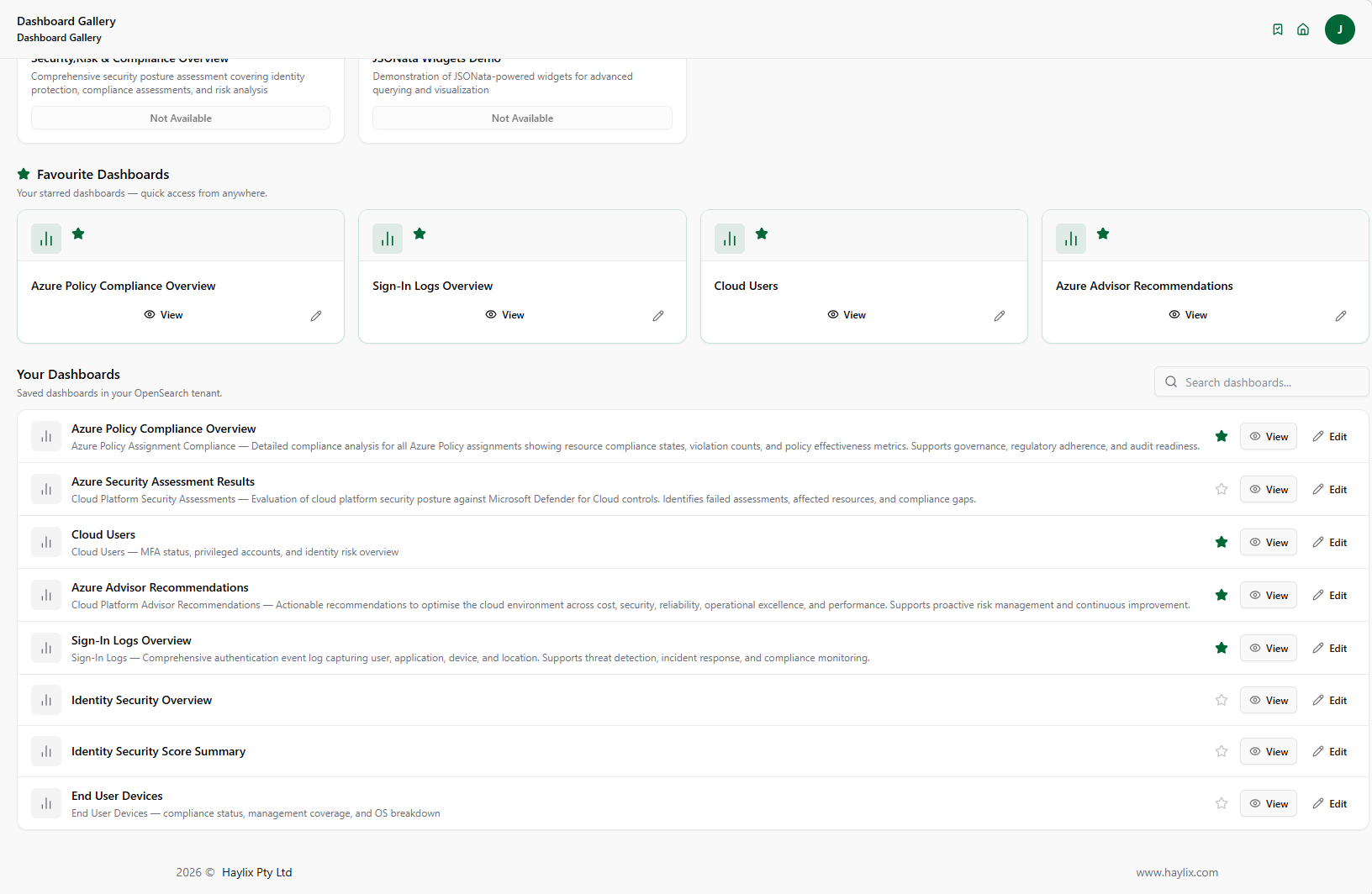
- Dashboard existence — does a production dashboard exist that reflects the service’s current operational state?
Each check is evaluated per service, giving developers a clear view of instrumentation gaps for the workloads they own.
Developer-Friendly Observability Output
Developers receive an Observability Action Pack tailored to service-level instrumentation:
- A service-by-service breakdown of instrumentation coverage with gap identification
- Code-level guidance for common instrumentation patterns (OpenTelemetry, Application Insights, CloudWatch)
- Dashboard template recommendations for each service type
- Alert configuration templates for the most common service-level error and latency patterns
Making Observability a Definition-of-Done Item
The most effective way to close observability gaps is to prevent them from forming. Developers who use Haylix ASSESS findings to inform their team’s definition of done ensure that new services meet a consistent observability baseline before they are declared production-ready.
Haylix ASSESS supports this by providing:
- A baseline score for each service that can be included in production readiness checklists
- A rescore capability that confirms instrumentation improvements after implementation
- Team-level aggregated scores that allow development leads to set and track instrumentation standards
From Reactive to Proactive Observability
The shift from reactive observability (discovering gaps during incidents) to proactive observability (verifying coverage before incidents occur) has a measurable impact on mean time to detect and mean time to resolve for cloud services.
Developers who run observability assessments as part of their pre-production process and use rescore after each sprint to maintain coverage typically report a significant reduction in the time spent diagnosing production issues — because the instrumentation needed to diagnose those issues was already in place when they occurred.